All you need to know about storage in DBMS

Software Engineer
Introduction
In the realm of databases, we often interact with them from the logical interface, focusing on tables, columns, data normalization ...etc. However, the details of how these tables are stored, their physical location, whether in RAM or Disk and the mechanisms involved in retrieving data maybe remain a mystery to us. In this article, we will delve into the world of database storage, bringing these issues to light and gaining a deeper understanding of how data is stored and accessed within a database.
Some Storage Concepts
Before getting into the details of DBMS data storage let's recap some CS fundamentals on storage.
Devices Volatility
Volatile devices mean that if you pull the power from the machine, then the data is lost. Volatile storage supports fast random access with byte-addressable locations. This means that the program can jump to any byte address and get the data that is there.
On the other hand, Non-volatile devices do not require continuous power in order for the device to retain the bits that it is storing.
Also, these devices are block/page addressable. This means that in order to read a value at a particular offset, the program first has to load the whole block/page into memory that holds the value the program wants to read.
Sequential vs. Random Access
Sequential access is when data is read or written in a sequentially ordered manner.
Random access is when data is read or written in an unordered manner.
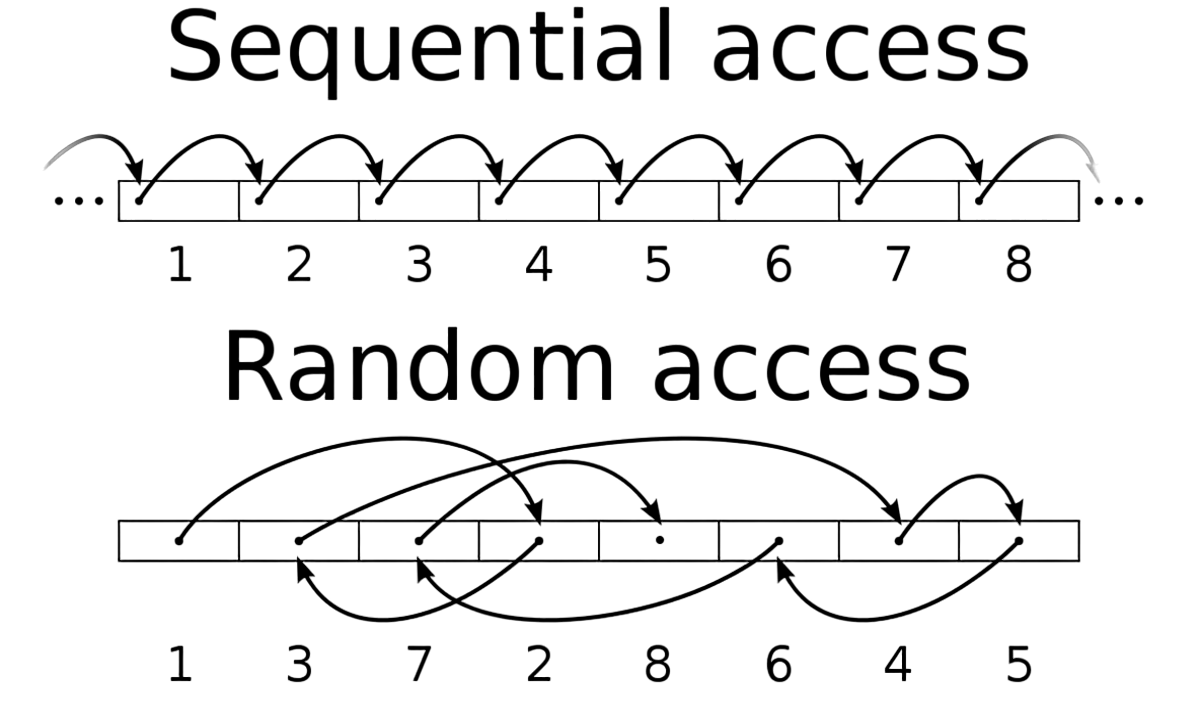
this article explains the details in very simple words. What we need to remember here is Random access on non-volatile storage is almost always much slower than sequential access.
In general, DBMS will want to maximize sequential access and the Implementation Algorithms that reduce the writes to random pages so that data is stored in contiguous blocks.
Storage Hierarchy
The last thing we want to recap is the computer storage hierarchy. we all know that the devices that are closest to the CPU. are the fastest storage, but it is also the smallest and most expensive. And the further we get away from the CPU, the larger but slower the storage devices get.
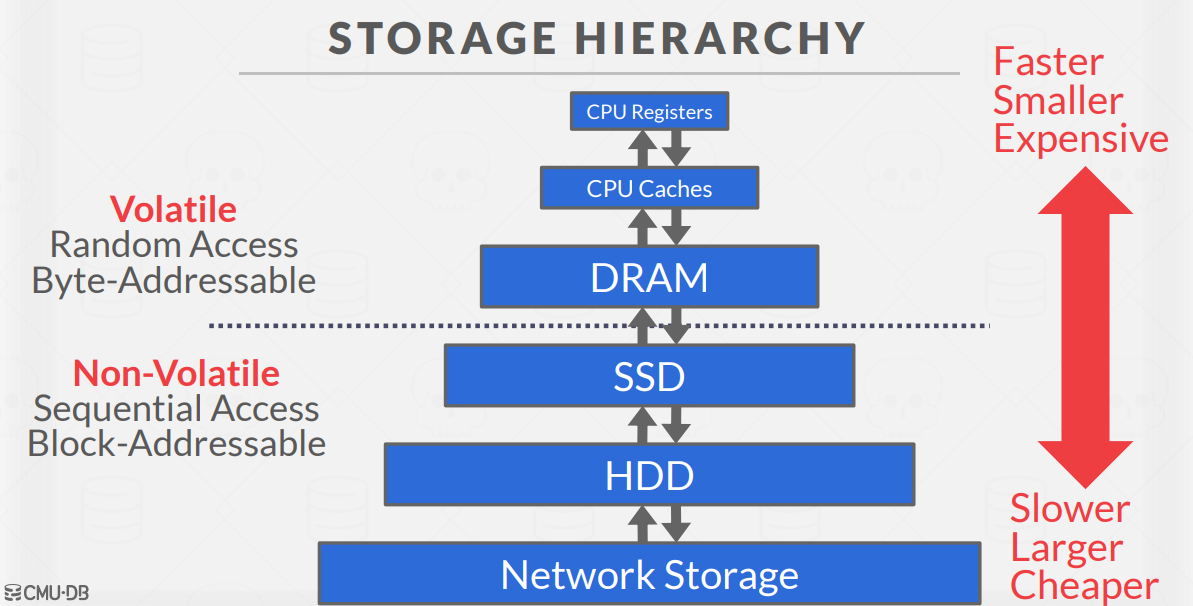
Databases Storage Types
DBMSs can be categorized based on the storage technology they employ. and we can suppress and say there are 2 types:
Disk-oriented Databases: In these databases, the primary storage location of data is on non-volatile disk(s).
In-Memory Databases: store data primarily in main memory (RAM) instead of disk storage.
I encourage you to read this thread in StackOverflow on Difference between In-memory databases and disk memory database.
As the main reference for us in this series is the CMU 15-445/645 course we will focus of Disk-oriented DBMS architecture assumes that the primary storage location of the database is on non-volatile disk(s)
Disk-Oriented DBMS Overview
In the Disk-oriented DBMS the database is all on disk but it does not operate on disk. Most DBMS store their data on disk so we can have the advantages of large disk sizes, and data safety. But when we want to access the data to manipulate it, we move the data from disk to memory, so we can get the advantage of high access times, this means the data is always moving back and forth from disk to memory.
Buffer Pool and Execution Engine
Due to the limited size of memory compared to the disk, it is crucial to have a mechanism in place to control the movement of data between the disk and memory. This ensures that the process is managed efficiently, preventing crashes and addressing scenarios when the memory becomes full.
So in DBMS, we have what is called a Buffer Pool, the buffer pool manager is responsible for managing the supply of DBMS with the page requested and making sure that this page will be in memory. ( we will visit the buffer pool in later articles )
The DBMS also has an execution engine that will execute queries.
So here is a sample query execution scenario:
The
execution enginewill ask thebuffer poolfor a specific page.The
buffer poolwill take care of bringing that page into memory and giving the execution engine apointerto that page in memory.The
execution enginewill interpret the layout of the page.

But wait a minute, Did you hear about something like that before ...?!
Of course, you did! this is the same idea of Virtual memory in OS.
DBMS vs. OS
A high-level design goal of the DBMS is to support databases that exceed the amount of memory available.
Since reading/writing to disk is expensive, disk use must be carefully managed. We do not want large stalls from fetching something from disk to slow down everything else.
Stall in operating systems refers to the delay in processor execution that is caused by waiting for data to become available in memory
This high-level design goal is like virtual memory, where the OS provides the user with the illusion of having a very big main memory. This is done by treating a part of the disk as the memory (RAM).
Then, Why not use the OS?
Well, the operating system deals with pages at a lower level (hardware pages), perceiving them as mere bits and bytes in the main memory. It has no clue if there is a logical dependence between the pages or not. And it may replace a page that was important during the query execution, leading to a slowdown as when this page is needed, we will have to move it back to the main memory.
Additionally, relying on the OS for data movement will bring us a huge overhead as we will use system calls (mmap). There is a paper on why should not use mmap in your DBMS.
In contrast, when our DBMS manages page movement, we can optimize it for maximum query execution speed, ensuring that important pages remain in memory. This approach grants us both greater control and improved performance.
File Storage
In its most basic form, a DBMS stores a database as files on disk. Some may use a file hierarchy, others may use a single file (e.g., SQLite), and typically the files are in a proprietary format.
The operating system does not know anything about the content of these files. Only the DBMS knows how to decipher its contents since it is encoded in a way specific to the DBMS.
The DBMS’s storage manager is responsible for managing a database’s files:
It represents the files as a collection of pages.
Tracks data read/written to pages.
Tracks the available space in pages.
Some do their own scheduling for reads and writes to improve the spatial and temporal locality of pages.
Database Pages
The DBMS organizes the database across one or more files in fixed-size blocks of data called pages.
Pages can contain different kinds of data
(tuples, indexes, etc).Most systems will not mix these types within pages.
Some systems will require that pages are self-contained, meaning that all the information needed to read each page is on the page itself.
Page Identifiers
Each page is given a unique identifier. If the database is a single file, then the page id can just be the file offset.
Most DBMSs have an indirection layer that maps a page id to a file path and offset. The upper levels of the system will ask for a specific page number. Then, the storage manager will have to turn that page number into a file and an offset to find the page.
Page Size
Most DBMSs use fixed-size pages to avoid the engineering overhead needed to support variable-sized pages.
- For example, with variable-size pages, deleting a page could create a hole in files that the DBMS cannot easily fill with new pages.
There are three concepts/types of pages in DBMS:
Hardware page, this is the page that is specified by the Hard Disk (usually 4 KB).
OS page, this is the page that the OS can work with, and it is usually the same size as the Hardware page (4 KB).
Database page (1-16 KB).

Atomic Writes
The storage device (Hard Disk, RAM ...etc) ensures atomic writes of the hardware page size. This means if our database page size is equal to the hardware page size we will gain atomicity over the writes so if we attempt to write 4 KB to the disk, either the entire 4 KB is written or none of it is. But, if the database page size exceeds the hardware page size, the DBMS will have to take extra measures to ensure that the data gets written out safely since the program can get part way through writing a database page to disk when the system crashes.
Now let's explore how these pages are structured and organized.
Page storage architecture
Finding pages in a single database file is straightforward.
The formula to locate a specific page is simply the page number multiplied by the page size.

But What if we have multiple database files?

DBMSs have different strategies for managing pages in files on disk. One common approach is the Heap File Organization, where records or tuples are stored randomly within a file. Other approaches include Sequential/Sorted File Organization (ISAM), Tree File Organization, and Hashing File Organization. Each method has its own benefits and considerations. But we will go further explaining the Heap File Organization.
Heap File Organization
A heap file is an unordered set of files where records or tuples are stored in a random order, eliminating the need for sorting. In this method, metadata is used to track the existence of pages and the available free space on each page. Additionally, the files are designed to have the same size, and each page within the file is of equal size. Furthermore, every record or tuple is assigned a unique identifier.
There are two common ways to represent a heap file:
Linked List representation: In this approach, the pages within the file are linked together using pointers. Each page contains records/tuples, and there is a pointer from one page to the next, forming a linked list structure. if the DBMS is looking for a specific page, it has to do a sequential scan of the data page list until it finds the page it is looking for.
Page Directory representation: In this method, the DBMS creates special pages that track the locations of data pages along with the amount of free space on each page called page directory.

Pages Layout
Each page is divided into two main sections, the first one is the Page Header, and the second is Page Data.

Page Header
On every page of a database file, there is a page header that stores metadata related to the page. The page header provides essential information for interpreting and understanding the data stored within the page. The specific metadata stored in the page header can vary between different DBMSs.
Examples of metadata that can be stored in the page header include the page size, DBMS version, compression information, checksums for data integrity, and other relevant details. Each DBMS may have its own requirements and specifications regarding the contents of the page header.
Some DBMSs prefer to make their pages self-contained, meaning that the metadata within the page header contains all the necessary information for the DBMS to identify the page and its contents. However, the exact implementation and content of the page header depend on the specific design and requirements of the DBMS being used.
Page Data
When it comes to storing data in pages, there are various approaches to consider. There are three different methods for storing tuples or records within a page:
Tuple Oriented Approach
Slotted Pages Approach
Log-Structured Approach
Tuple-Oriented Approach
In this approach, the page header contains information about the number of tuples stored on the page. To add a new tuple, we append its data to the existing page data at the first free space it finds, and update the number of tuples.
If we want to delete some record we find, delete it and update the number of tuples in the page header. This results in the following structure for our pages:

This approach has several drawbacks:
Firstly, it assumes that all records/tuples have the same length. However, in reality, records often have variable lengths, especially when dealing with attributes like blobs or strings that can vary in size. This limitation prevents us from efficiently locating the appropriate position for inserting a new record in the page.
Secondly, deletions in this approach lead to page fragmentation. After each deletion, free spaces are left between the remaining data, resulting in inefficient storage utilization. To address this issue, we would need to periodically compact the data or perform compaction after each deletion, which can be resource-intensive. Alternatively, when inserting new records, we would need to search sequentially for available free spaces until one is found, which affects
Due to these limitations, is not commonly used in practice. and this approach is often referred to as the "Strawman Idea".
- Slotted Pages Approach
This is the most common approach used in DBMSs today. Our page is divided into slots, a header, and data:
In the header, we keep track of the number of used slots, the offset of the starting location of the last used slot, and a slot array, which keeps track of the location of the start of each tuple in the data section. Our page will be like this:
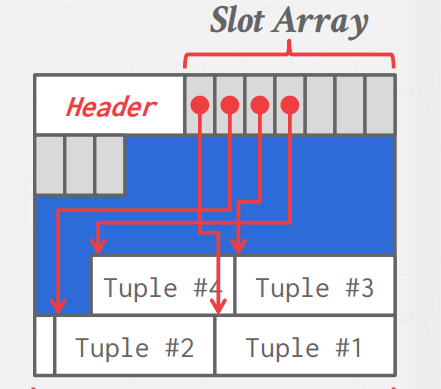
To add a tuple, the slot array (header section) will grow from the beginning to the end, and the data of the tuples (data section) will grow from the end to the beginning.
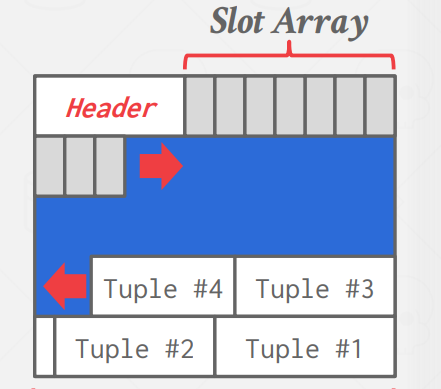
The page is considered full when the slot array and the tuple data meet.
Some problems associated with the Slotted-Page Design are:
Page Fragmentation: Deletion of tuples can leave gaps in the pages.
Useless Disk I/O: Due to the block-oriented nature of non-volatile storage, the whole block needs to be read to fetch a tuple.
Random Disk I/O: The disk reader could have to jump to 20 different places to update 20 different tuples, which can be very slow.
What if we were working on a system that only allows the creation of new data and no overwrites?
The log-structured storage model works with this assumption and addresses some of the problems listed above.
- Log-Structured Approach
The idea of this approach is instead of storing tuples, the DBMS only stores log records. Store records to file of how the database was modified (PUT and DELETE).

Each log record contains the tuple’s unique identifier. To read a record, the DBMS scans the log file backward from newest to oldest.
Instead of scanning all records to find a specific record, we can maintain an index that maps a tuple id to the newest log record.

This approach offers fast write operations by leveraging sequential disk writes and the immutability of existing pages, reducing random disk I/O. However, it may result in slower read operations. It works effectively on append-only storage systems where data is not updated or modified after it is written.
Log-structured compaction
To mitigate the potential slowness of reads, the DBMS can employ indexes to quickly navigate to specific locations within the log. Periodic log compaction can also be performed, where updates are consolidated to minimize redundancy and optimize storage.
The database can compact the log into a sorted table based on record IDs, discarding the temporal information that is no longer needed. These sorted tables, known as Sorted String Tables (SSTables), enable fast tuple search operations.
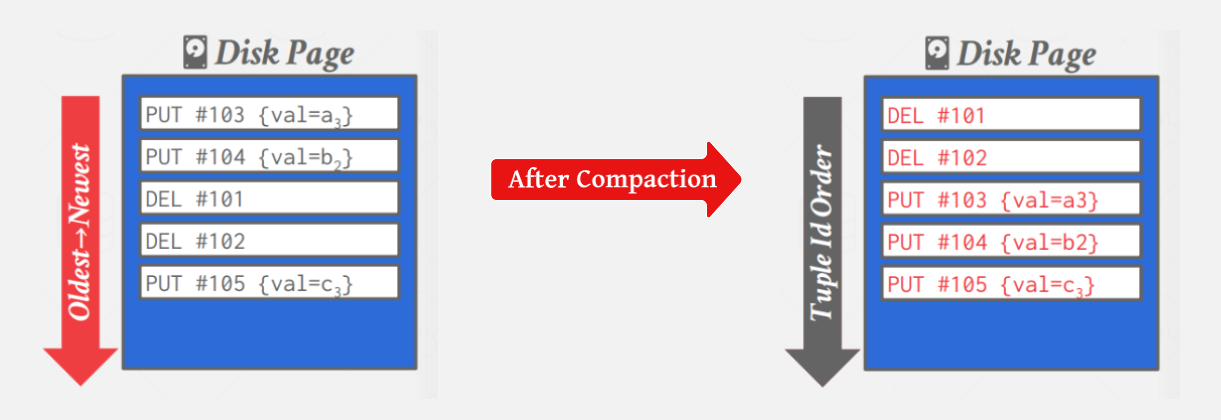
However, the issue with compaction is that it can lead to "write amplification", where the DBMS repeatedly rewrites the same data, resulting in increased write overhead.
Tuple Layout
After exploring how data is organized in files and pages, we now turn our attention to a tuple itself. A tuple is essentially a sequence of bytes, and it is the DBMS’s job to interpret those bytes into attribute types and values.
Each DBMS stores tuples in its own way, and it all depends on the implementation details of the specific DBMS. but we can separate the tuple structure into two main sections:

Tuple Header contains metadata about the tuple.
Visibility information for concurrency control protocol ( will be explained later)
Bit Map for NULL values.
Tuple Data, the actual data of the tuple
Attributes attribute values of the tuple (typically stored in the order that you specify them when you create the table).
Most DBMSs do not allow a tuple to exceed the size of a page.
Record ID (Unique Identifier)
Each tuple in the database is assigned a unique identifier
The most common way to construct a unique ID for the tuple is page_id+(offset or slot number)*.* Can also contain file location info.
This is not the primary key of the tuple. So the application cannot rely on these IDs to mean anything.
In different DBMSs, it has different names, e.g. PostgreSQL called ctid, SQLite rowid.
Denormalized Tuple Data
If two tables are related, the DBMS can physically denormalize (e.g. pre-join” ) them, so the tables end up on the same page.

This makes reads faster since the DBMS only has to load in one page rather than two separate pages. However, it makes updates more expensive since the DBMS needs more space for each tuple.
Tuple Data Representation
The data in a tuple is essentially just byte arrays. It is up to the DBMS to know how to interpret those bytes to derive the values for attributes. A data representation scheme is how a DBMS stores the bytes for a value.
There are five high-level data types that can be stored in tuples: Integers, Variable-precision numbers, Fixed-point precision numbers, Variable length values, and Dates/Times.
Integers in DBMSs are stored using fixed-length native C/C++ types (e.g., INTEGER, BIGINT). Variable precision numbers, also fixed-length, use native C/C++ types (e.g., FLOAT, REAL), enabling faster computations but with potential rounding errors. Fixed-point precision numbers offer arbitrary precision and scale, stored as a variable-length binary representation with metadata, ensuring accuracy at the cost of performance (e.g., NUMERIC, DECIMAL).
Variable-Length Data
These represent data types of arbitrary length. They are typically stored with a header that keeps track of the length of the string to make it easy to jump to the next value. It may also contain a checksum for the data.
Large Values
Most DBMSs do not allow a tuple to exceed the size of a single page.
The ones that do store the data on a special “overflow” page and have the tuple contain a reference to that page.
Postgres: TOAST (>2KB)
MySQL: Overflow (>½ size of page)
SQL Server: Overflow (>size of page)
These overflow pages can contain pointers to additional overflow pages until all the data can be stored.
External Value Storage Some systems will let you store these large values in an external file, and then the tuple will contain a pointer to that file. For example, if the database is storing photo information, the DBMS can store the photos in external files rather than having them take up large amounts of space in the DBMS.
One downside of this is that the DBMS cannot manipulate the contents of this file. Thus, there are no durability or transaction protections. Examples: VARCHAR, VARBINARY, TEXT, BLOB.
Dates and Times
Representations for date/time vary for different systems. Typically, these are represented as some unit time (micro/milli)seconds since the UNIX epoch. Examples: TIME, DATE, TIMESTAMP.
System Catalogs
To ensure the DBMS can interpret tuple contents, it maintains an internal catalog containing metadata about the databases.
This includes information about tables, columns, indexes, views, users, permissions, and internal statistics. Typically, DBMSs store their catalogs in the same format as their tables, employing specialized code for catalog table initialization. By querying the DBMS's internal INFORMATION_SCHEMA catalog, users can obtain comprehensive details about the database, utilizing the ANSI standard set of read-only views that offer insights into tables, views, columns, and procedures.
Conclusion
In this article, we explored the world of storing and accessing data in databases. We discussed the basics of storage devices, how we can access data in different ways, and the different levels of storage. We then focused on a specific type of database system that uses disks for storage. We looked at how files are stored, the structure of database pages, and how individual pieces of data are stored within those pages. By understanding these concepts, we gained a better understanding of how data is organized and retrieved in a database management system.




